Table of Contents
1 问题表现 Link to 1 问题表现
起因是在测试 triton-cpu在 x86 上的性能表现,但是执行 softmax_triton.py 之后就发现触发了非常奇怪的 Illegal instruction (core dumped)

2 问题定位 Link to 2 问题定位
由于只有 softmax 会产生这个问题,所以应该是只有 softmax 中使用的操作导致的。
softmax 的代码如下
1234567891011121314151617181920212223242526272829@triton.jit
def softmax_kernel(
output_ptr,
input_ptr,
input_row_stride,
output_row_stride,
n_cols,
BLOCK_SIZE: tl.constexpr,
):
# The rows of the softmax are independent, so we parallelize across those
row_idx = tl.program_id(0)
# The stride represents how much we need to increase the pointer to advance 1 row
row_start_ptr = input_ptr + row_idx * input_row_stride
# The block size is the next power of two greater than n_cols, so we can fit each
# row in a single block
col_offsets = tl.arange(0, BLOCK_SIZE)
input_ptrs = row_start_ptr + col_offsets
# Load the row into SRAM, using a mask since BLOCK_SIZE may be > than n_cols
row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float("inf"))
# Subtract maximum for numerical stability
row_minus_max = row - tl.max(row, axis=0)
# Note that exponentiation in Triton is fast but approximate (i.e., think __expf in CUDA)
numerator = tl.exp(row_minus_max)
denominator = tl.sum(numerator, axis=0)
softmax_output = numerator / denominator
# Write back output to DRAM
output_row_start_ptr = output_ptr + row_idx * output_row_stride
output_ptrs = output_row_start_ptr + col_offsets
tl.store(output_ptrs, softmax_output, mask=col_offsets < n_cols)
经过几轮测试,其中的 exp 调用了 libsleef 库,导致了这个问题。将 exp 去掉之后问题消失。
阅读一下 ~/.triton/cache 中生成的汇编程序,也可以发现,exp 操作是调用了一个叫做 Sleef_expf16_u10(编译一次时间太长,这里图片直接放修复后的结果了)
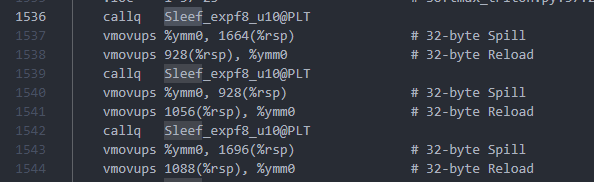
问题就出在这个 Sleef_expf16_u10 他是 AVX512F 指令集下才支持的,但是我用 lscpu 一看,我的 intel i7-10875 只支持 avx2。这不就破案了吗。
3 问题修复 Link to 3 问题修复
已知问题出现在调用 sleef 库的 Sleef_expf16_u10 上,那么问题一定就在 triton 的 lowering 过程中。直接在 triton 的代码仓库中搜索,很快可以找到 benchmarks/triton-cpu/third_party/cpu/lib/TritonCPUToLLVM/MathToVecLib.cpp 这个文件,其中包含了如何将 Math 函数 lowering 到 VecLib。这里的 VecLib 指的就是 sleef 库。
仔细查看就能发现这里对
12345678910111213141516171819202122232425//benchmarks/triton-cpu/third_party/cpu/lib/TritonCPUToLLVM/MathToVecLib.cpp
class SleefNameGenerator {
public:
SleefNameGenerator(StringRef baseName, unsigned ulp = 10)
: baseName(baseName), ulpSuffix(4, '\0') {
if (ulp == 0) {
ulpSuffix = "";
} else {
char buf[5]; // 4 char suffix + '\0' added by snprintf
snprintf(buf, 5, "_u%02u", ulp);
ulpSuffix = buf;
}
}
std::string operator()(unsigned bitwidth, unsigned numel,
ValueRange /*operands*/) const {
if (bitwidth != 32 && bitwidth != 64)
return "";
unsigned vecSize = numel * bitwidth;
if (vecSize < 128)
return "";
return "Sleef_" + baseName + (bitwidth == 32 ? "f" : "d") +
std::to_string(numel) + ulpSuffix;
}
显然就是这里在选择 sleef 的函数时出现了问题,找到 SleefNameGenerator 的调用,这里明显有一个设置 vec_size_in_bits 与指令集相关,直接向下跳转查找这个 vec_size_in_bits 的定义。
12345678910111213141516171819202122232425262728293031323334//benchmarks/triton-cpu/third_party/cpu/lib/TritonCPUToLLVM/MathToVecLib.cpp
void runOnOperation() override {
Operation *op = getOperation();
MLIRContext *context = op->getContext();
RewritePatternSet patterns(context);
switch (lib) {
case VecLib::Mvec: {
populateCommonPatterns<MvecNameGenerator>(patterns);
break;
}
case VecLib::Sleef: {
populateCommonPatterns<SleefNameGenerator>(patterns);
populatePatternsForOp<math::ExpM1Op>(
patterns, SleefNameGenerator("expm1"), vec_size_in_bits);
populatePatternsForOp<math::FloorOp>(
patterns, SleefNameGenerator("floor", /*ulp=*/0), vec_size_in_bits);
populatePatternsForOp<math::SqrtOp>(
patterns, SleefNameGenerator("sqrt", /*ulp=*/5), vec_size_in_bits);
populatePatternsForOp<math::TruncOp>(
patterns, SleefNameGenerator("trunc", /*ulp=*/0), vec_size_in_bits);
break;
}
}
patterns.add<DecomposeToNativeVecs<ExternElementwiseOp>>(
patterns.getContext(), vec_size_in_bits);
patterns.add<PadSmallVecsForSleef>(patterns.getContext());
patterns.add<ExternElementwiseOpConversion>(patterns.getContext());
if (failed(applyPatternsAndFoldGreedily(op, std::move(patterns))))
signalPassFailure();
}
发现这是一个类内的成员变量,继续查找更新这个变量的地方。来到 355 行一看,原来这里有个 TODO!这里直接没有管你到底是什么指令集,通通按照 AVX512 的位宽进行处理,怪不得会报 Illegal instruction,果然是不支持的指令。
123456789101112131415//benchmarks/triton-cpu/third_party/cpu/lib/TritonCPUToLLVM/MathToVecLib.cpp
void update_vec_size(std::set<std::string> &cpu_features) {
// TODO:
// Refactor this as an independent function.
// And improve this to support other x86 SIMD ISAs and also for arm SVE
// (VLA)
vec_size_in_bits = 512;
for (auto feature : cpu_features) {
// Arm NEON is fixed 128-bit SIMD ISA.
if (feature == "neon") {
vec_size_in_bits = 128;
break;
}
}
}
找到问题就很好办了,直接加几个 if-else,根据 feature 设置一下位宽
123456789101112131415161718192021222324//benchmarks/triton-cpu/third_party/cpu/lib/TritonCPUToLLVM/MathToVecLib.cpp
void update_vec_size(std::set<std::string> &cpu_features) {
// TODO:
// Refactor this as an independent function.
// And improve this to support other x86 SIMD ISAs and also for arm SVE
// (VLA)
vec_size_in_bits = 0;
for (auto feature : cpu_features) {
// Arm NEON is fixed 128-bit SIMD ISA.
if (feature == "neon") {
vec_size_in_bits = 128;
break;
} else if (feature == "avx512f") {
vec_size_in_bits = vec_size_in_bits > 512 ? vec_size_in_bits : 512;
} else if (feature == "avx2") {
vec_size_in_bits = vec_size_in_bits > 256 ? vec_size_in_bits : 256;
} else if (feature == "avx") {
vec_size_in_bits = vec_size_in_bits > 256 ? vec_size_in_bits : 256;
}
}
if (vec_size_in_bits == 0) {
vec_size_in_bits = 512;
}
}
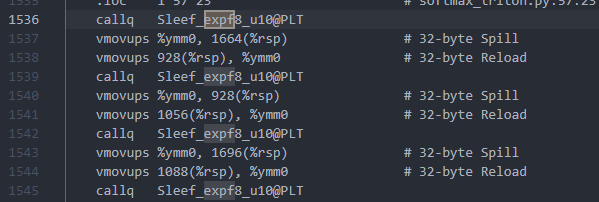
再进行测试,果然通过了。回头查看一下生成的汇编代码,也不是 Sleef_expf16_u10 了,而是 avx2 支持的 Sleef_expf8_u10。问题完美解决,尝试给 triton-cpu 提交一个PR,希望能被接收:[MathToVecLib] Add support for setting bit-widths for AVX512, AVX, and SSE to prevent “Illegal instruction (core dumped)” by Artlesbol · Pull Request #234 · triton-lang/triton-cpu
修复triton-cpu调用sleef生成非法指令
© Artlesbol 版权所有,依据 CC-BY-NC-SA 4.0 协议开源